

⚙️ Prep 22 - Tuning Spark Executors: The Art of Core, Memory, and Parallelism
How do you decide the number of executors, executor cores, and memory in a Spark job?

In Spark, your job’s performance hinges on more than just good code. It's also about how many executors you spin up, how many cores they get, and how much memory each is assigned.
Mess up the tuning? You’ll face:
OOMs (Out of Memory errors)
Inefficient garbage collection
Wasted cluster resources
Sluggish job performance
In today’s DE Prep, we take you from raw hardware to optimal executor settings — with full math, examples, and rules.
🔧 What Is a Spark Executor?
An executor in Spark is a JVM process launched on a worker node to:
Run tasks (units of computation)
Store intermediate shuffle data
Cache RDDs or DataFrames in memory
Communicate with the driver
Each executor is configured with:
executor cores: number of concurrent tasks it can run
executor memory: heap space available for computation and storage
Why It Matters:
Bad executor tuning leads to:
Excessive garbage collection (GC)
Idle cores
Memory spills and disk IO
Cluster underutilization
💻 Cluster Context
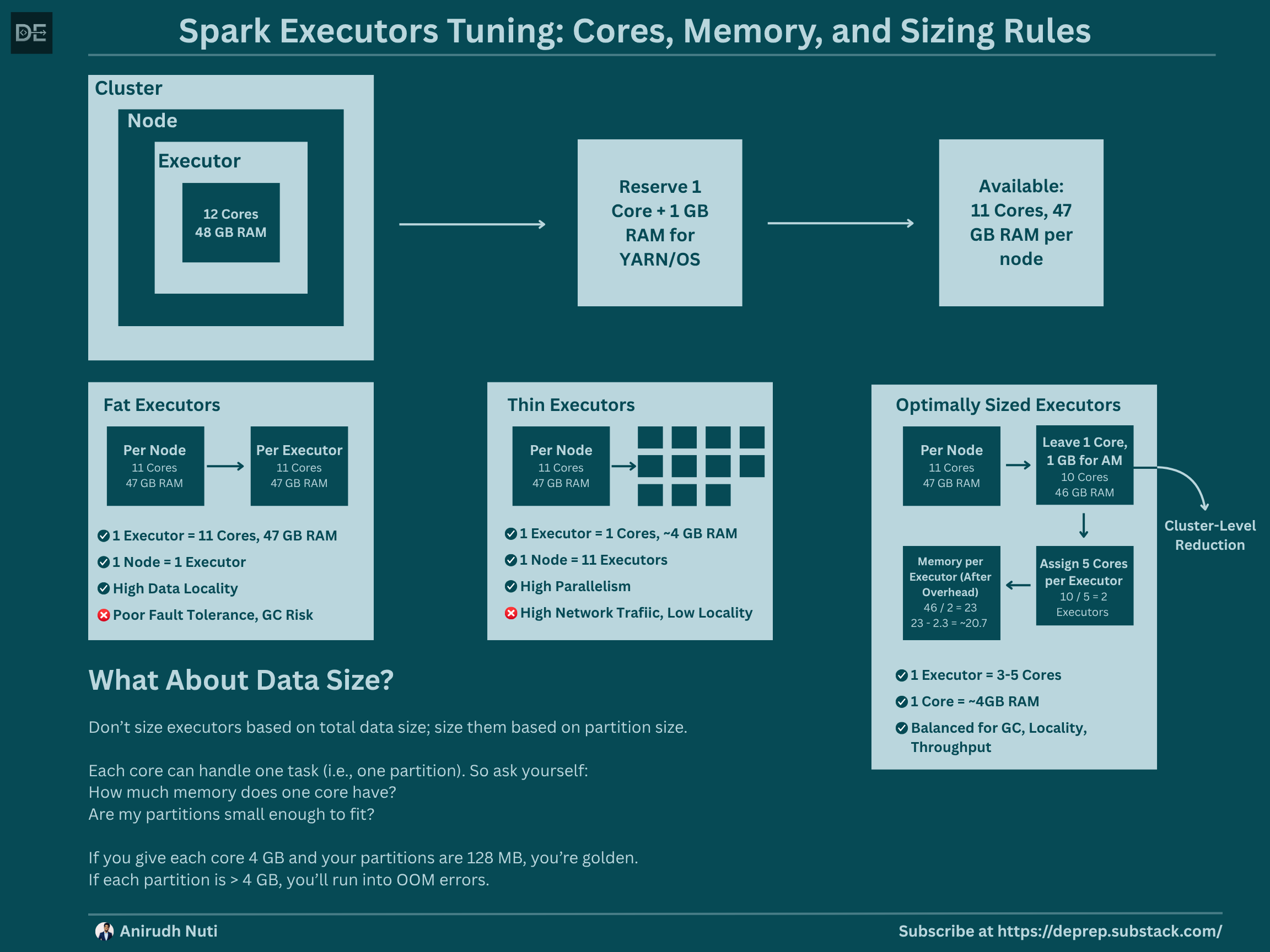
Let’s take a cluster of 5 nodes (VMs), where each node has:
12 Cores
48 GB RAM
You have three options:
Fat Executors: Occupy almost all resources on a node
Thin Executors: Occupy minimal resources, so you can spawn many
Optimally Sized Executors: Balance between parallelism and memory management
🛢️ Fat Executors
Fat Executors are large, powerful, and occupy a significant number of resources in the cluster. Example:
Leave 1 core and 1 GB RAM for OS/YARN (Per Node), which means we will have 11 cores and 47 GB of RAM per node.
Since fat executors are designed to consume the majority of a node’s resources, a single fat executor would utilize the entire available capacity, all 11 cores, and 47 GB of RAM on that node.
You’ll end up with:
5 executors (1 per node)
Each with 11 cores and 47 GB of memory
--num-executors = 5
--executor-cores = 11
--executor-memory = 47✅ Advantages of Fat Executors
Increased Parallelism
Fat executors have more cores, allowing them to run multiple tasks in parallel, which can significantly boost performance. They're especially useful when:
Tasks need to load and process large volumes of data in memory
Managing a high number of executors is operationally challenging
Better Data Locality
With fewer but larger executors, more data can be cached in memory per executor. This increases the chances of processing data locally (on the same node where it's stored), which:
Minimizes shuffling across the network
Improves overall application throughput
❌ Disadvantages of Fat Executors
Resource Underutilization
If the workload doesn’t fully leverage all allocated cores or memory, the unused resources sit idle, leading to inefficiency.
Reduced Fault Tolerance
When an executor handles a large portion of data, its failure is more damaging. Recomputing lost work can take significant time, reducing application reliability.
Lower HDFS Throughput
Using too many cores per executor (especially >5) can negatively impact HDFS read/write throughput. This is due to increased garbage collection and memory pressure. Spark generally performs best with 3–5 cores per executor to maintain stable throughput and minimize GC overhead.
🧵 Thin Executors
Thin Executors are the opposite of fat executors; they are small, numerous, and occupy minimal resources in a cluster. Example:
Leave 1 core and 1 GB RAM for OS/YARN (Per Node), same as fat executors, which means we will have 11 cores and 47 GB of RAM per node.
Since thin executors are designed to use minimal resources, each one is allocated just a single core, meaning 1 executor = 1 core. With 11 available cores per node, this results in 11 executors per node.
For memory, the 47 GB of RAM on the node is evenly divided across these 11 executors:
Memory per executor = 47 ÷ 11 ≈ 4 GB.Use 1 core & ~4 GB RAM per executor
You’ll end up with:
11 executors per node × 5 nodes = 55 executors
Each with 1 core and ~4 GB RAM
--num-executors = 55
--executor-cores = 1
--executor-memory = 4✅ Advantages of Thin Executors
Increased Parallelism
Increases parallelism as there are more executors handling smaller tasks. This is beneficial when tasks are lightweight.
Fault Tolerance
One executor going down amounts to losing a small unit of work done, which is easier to recover.
❌ Disadvantages of Thin Executors
High Network Traffic
Thin executors may increase network traffic because each executor has a small memory, and therefore, data has to be distributed across more executors for processing.
Reduced Data Quality
Having think executors spread across multiple nodes can reduce the effectiveness of data quality.
🧠 Optimal Executor Sizing - The 4 Rules
There are 4 rules that you should keep in mind when optimizing the executor sizing. To strike a balance, follow this playbook:
Rule 1: Leave 1 Core + 1 GB per Node for OS and YARN
You don’t want Spark competing with the OS or Hadoop daemons.
Rule 2: Reserve for ApplicationMaster (Cluster Level)
The ApplicationMaster is responsible for negotiating resources with the cluster’s ResourceManager and coordinating the execution of Spark tasks.
Either:
Subtract 1 core + 1 GB RAM
OR subtract 1 executor (preferably only if executors are small)
Rule 3: 3 to 5 Cores per Executor
Too few = not enough parallelism.
Too many = garbage collection chaos.
3–5 cores hit the sweet spot for CPU utilization and GC safety.
Rule 4: Subtract Memory Overhead
When you assign executor memory, Spark also reserves memory overhead:
spark.yarn.executor.memoryOverhead= max(384MB, 10% of executor memory)
If you assign 23 GB, the actual usable executor memory will be ~20.7 GB.
🔢 Example 1 (for optimally sized executors following the above rules): 5-Node Cluster with 12 Cores & 48 GB Each
Step-by-Step:
1. Leave OS/YARN overhead (per node):
12 cores – 1 = 11
48 GB – 1 GB = 47 GB
2. Cluster total:
11 cores × 5 = 55 cores
47 GB × 5 = 235 GB
3. Leave 1 core + 1 GB for ApplicationMaster
55 – 1 = 54 cores
235 – 1 = 234 GB
4. Assign 5 cores per executor
54 ÷ 5 = 10 executors
5. Memory per executor (before overhead):
234 ÷ 10 = 23.4 GB
6. Subtract overhead (10%):
23.4 – 2.34 = ~21 GB
Final config:
10 executors
5 cores per executor
21 GB per executor
--num-executors = 10
--executor-cores = 5
--executor-memory = 21🔢 Example 2: 3-Node Cluster with 16 Cores & 48 GB Each
1. Per node resources:
15 cores, 47 GB
2. Cluster total:
15 × 3 = 45 cores
47 × 3 = 141 GB
3. Subtract for ApplicationMaster:
44 cores, 140 GB
4. Assign 4 cores per executor:
44 ÷ 4 = 11 executors
5. Memory per executor:
140 ÷ 11 = ~12.7 GB → round to 12 GB
6. Subtract memory overhead (1.2 GB):
12 – 1.2 = 10.8 GB
Final config:
11 executors
4 cores per executor
~11 GB memory per executor
--num-executors = 11
--executor-cores = 4
--executor-memory = ~11🧪 But What About Data Size?
Great question.
You don’t size executors based on total data size - you size them based on partition size.
Each core can handle one task (i.e., one partition). So ask yourself:
❓ “How much memory does one core have?”
❓ “Are my partitions small enough to fit?”
If you give each core 4 GB and your partitions are 128 MB, you’re golden.
If each partition is > 4 GB, you’ll run into OOM errors.
🔁 Summary: Optimally Tuned Executors
Cores per Executor: Use 3 to 5 cores per executor
Executors per Cluster: Calculate as (total available cores ÷ cores per executor)
Executor Memory:
(Total cluster RAM – 1 GB per node – 1 GB for ApplicationMaster) ÷ number of executors, then subtract memory overheadMemory Overhead:
Reserve the greater of 384MB or 10% of executor memoryCore-to-Memory Ratio:
Aim for ~3–4 GB of memory per core for balanced performance
✅ Benefits of Optimal Sizing
Balanced parallelism
Enhanced data locality
Minimal GC stalls
Lower risk of executor failure
Predictable partition processing
🚀 TL;DR
Don’t let Spark auto-tune for you. Take control.
Use:
3–5 cores per executor
1 core = 3–4 GB of memory
Subtract YARN, OS, and overhead memory
And always ask:
“Does one core have enough memory to handle one partition?”
If yes → you're good to go.
Infographic
👉 Follow DE Prep to stay sharp with real-world data engineering problems and practical guides. Let’s make Spark performance less of a black box - one prep at a time.
View all DE Preps categorized in one place at DEtermined