

🚀 Prep #21 - Demystifying Spark Memory Management: One Block at a Time
Explain Spark's memory management system. What is unified memory? How is executor memory calculated and allocated? What’s the role of off-heap memory?

If your Spark job is spilling to disk, running out of memory, or performing sluggishly on joins, there’s a good chance the culprit is memory mismanagement. Welcome to Prep 21, where we roll up our sleeves and dive deep into how Spark handles memory under the hood - from JVM-managed heaps to unified memory pools and off-heap optimizations.
Let’s break it down.
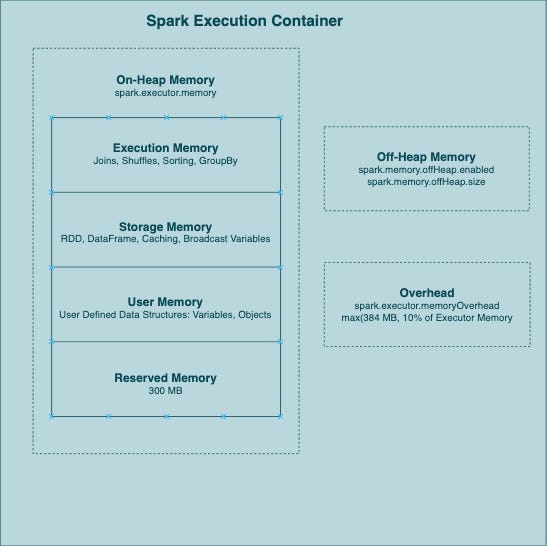
🔍 The Spark Executor Memory Blueprint
Each Spark executor has its own memory slice, like a sandboxed mini-environment.
Here's how that memory gets divided:
On-Heap Memory – Lives in the JVM. Default playground for Spark's operations.
Overhead Memory – OS-level buffer used by Spark for housekeeping tasks.
Off-Heap Memory – An optional escape hatch managed by the OS to bypass JVM garbage collection.
Here’s what lives inside the on-heap memory:
Execution Memory – For joins, sorts, shuffles, and aggregations.
Storage Memory – For caching datasets and storing broadcast variables.
User Memory – Custom variables, collections, and UDFs.
Reserved Memory – System-level Spark operations (~300MB by default).
🧮 How Spark Allocates Memory: A Real Example
Say you’ve configured:
spark.executor.memory = 50 (GB)Spark will allocate memory roughly like this:
Unified Memory Pool:
50GB * 0.6= 30GBStorage (half of the entire unified memory pool):
0.5 * 30GB= 15GBExecution: Remaining = 15GB
User + Reserved Memory: 20GB (of which 300MB is reserved, and ~19.7GB is User memory)
Then comes the overhead:
spark.executor.memoryOverhead = max(384MB, 10% of executor memory)
= max(384MB, 5GB) = 5GBIf the full 50GB of executor memory is dedicated to on-heap memory, Spark still needs room for overhead and optional off-heap memory. These are not part of the 10GB, Spark requests additional memory from the cluster manager to accommodate them.
So, for example:
With
spark.executor.memory=50GBand default overhead of 5GB → Spark will request 55GB per executor.If off-heap is enabled (say 5GB, usually around 10-20% of executor memory) → Total memory requested becomes 60GB per executor.
In short, executor memory covers only the on-heap portion. Overhead and off-heap memory are extra allocations requested from the cluster manager.
🧠 Unified Memory: The Dynamic Duo
Spark >= 1.6 introduced Unified Memory Management - a more intelligent way to juggle execution and storage needs.
Spark < 1.6:
Execution and storage had fixed-size walls. Unused storage couldn’t help execution.
Spark >= 1.6:
Memory is shared. If execution needs more space, it can “steal” from storage.
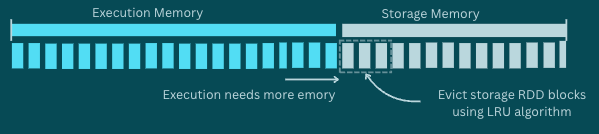
Execution gets priority. That means, if storage needs more space, it can’t “steal” memory from execution. Instead, it must free up its own space by evicting cached blocks using the LRU (Least Recently Used) algorithm.
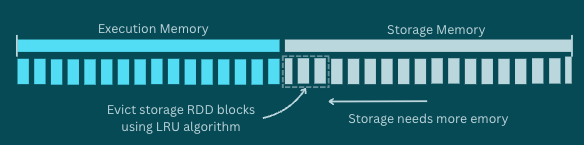
So memory becomes fluid, but biased towards performance-critical tasks.
💡 What About Off-Heap Memory?
When your on-heap memory is stressed and GC (Garbage Collection) kicks in too frequently, Spark can pause your job just to clean up.
Off-heap memory offers a way out.
✅ GC-free (managed by the OS)
✅ Optional and configurable
❌ Must manually manage allocation/deallocation
❌ Slightly slower than on-heap (but faster than disk!)
To use it:
spark.memory.offHeap.enabled = true
spark.memory.offHeap.size = 5gb # or ~10% of executor memoryUse with care. Improper cleanup = memory leaks.
⚠️ Common Mistakes to Avoid
Blindly caching DataFrames that won’t be reused.
Under-allocating executor memory and increasing parallelism instead.
Ignoring off-heap tuning while suffering GC delays.
🧩 Summary
Spark’s memory model is a set of moving pieces, with sliders, defaults, and priorities. Once you understand how execution and storage interact, and how overhead and off-heap fit in, you can tame even the most complex workloads.
If you’ve been avoiding memory tuning, Prep 21 is your call to action.
👉 Follow DE Prep to stay sharp with real-world data engineering problems and practical guides. Let’s make Spark performance less of a black box - one prep at a time.
View all DE Preps categorized in one place at DEtermined