

Prep #17 - Designing a Scalable Data Model for YouTube: A Database Architect's Guide
How to model a scalable, production-ready database for a video streaming platform?

YouTube's massive scale - with over 500 hours of video uploaded every minute - demands a carefully engineered data architecture. In this deep dive, we'll construct a production-ready database model that balances normalization for data integrity with practical optimizations for performance.
Entity-Relationship Diagram (ERD)
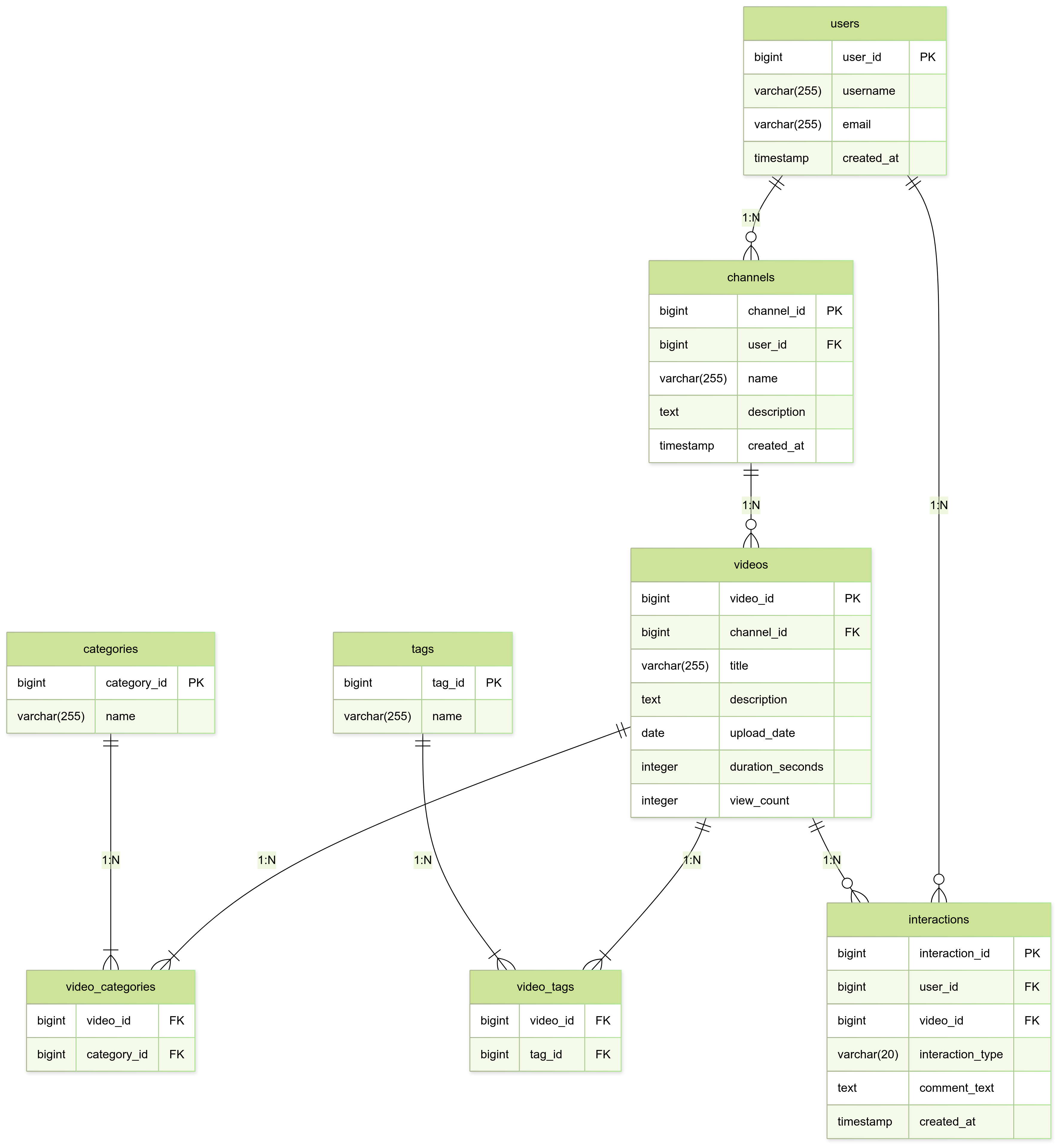
Key Relationships:
1. Users → Channels
One-to-Many
Each user can create multiple channels.
channels.user_idis a foreign key referencingusers.user_id.
2. Channels → Videos
One-to-Many
Each channel can upload multiple videos.
videos.channel_idis a foreign key referencingchannels.channel_id.
3. Videos → Interactions
One-to-Many
Each video can have multiple interactions (views, likes, comments).
interactions.video_idis a foreign key referencingvideos.video_id.
4. Users → Interactions
One-to-Many
Each user can interact with many videos.
interactions.user_idis a foreign key referencingusers.user_id.
5. Videos ↔ Tags
Many-to-Many via
video_tagsEach video can have multiple tags, and each tag can belong to many videos.
video_tags.video_id→videos.video_idvideo_tags.tag_id→tags.tag_id
6. Videos ↔ Categories
Many-to-Many via
video_categoriesEach video can belong to multiple categories, and each category can contain multiple videos.
video_categories.video_id→videos.video_idvideo_categories.category_id→categories.category_id
📈 Additional Notes
videosincludes aview_countcolumn for denormalized, fast-access statistics.Interactions are generic and polymorphic through the
interaction_typefield, which coversview,like,comment.
🏗️ Core Data Entities
1. Users: The Foundation
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(255) UNIQUE NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);Every YouTube journey begins with user accounts. We enforce uniqueness on both username and email to prevent duplicates, while SERIAL auto-increments IDs for efficient joins.
2. Channels: Creators' Home Bases
CREATE TABLE channels (
channel_id SERIAL PRIMARY KEY,
user_id INT REFERENCES users(user_id),
name VARCHAR(255) NOT NULL,
description TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);The one-to-many relationship (users → channels) allows creators like MrBeast to manage multiple channels under one account. The REFERENCES constraint ensures data integrity through foreign keys.
🎥 Video Management System
3. Videos: The Star Attraction
CREATE TABLE videos (
video_id SERIAL PRIMARY KEY,
channel_id INT REFERENCES channels(channel_id),
title VARCHAR(255) NOT NULL,
description TEXT,
upload_date DATE NOT NULL,
duration_seconds INT NOT NULL,
view_count INT DEFAULT 0 -- Denormalized for performance
);Key design choices:
duration_seconds uses integers for precise calculations (better than TIME for analytics)
Denormalized view_count avoids expensive COUNT(*) queries
REFERENCES maintains channel-video relationships
4. Categories & Tags: Content Discovery
CREATE TABLE categories (
category_id SERIAL PRIMARY KEY,
name VARCHAR(255) UNIQUE NOT NULL -- "Gaming", "Education", etc.
);
CREATE TABLE video_categories (
video_id INT REFERENCES videos(video_id),
category_id INT REFERENCES categories(category_id),
PRIMARY KEY (video_id, category_id) -- Composite PK
);The many-to-many junction table (video_categories) enables a single video to appear in multiple categories (e.g., a "Science" video could also be in "Education").
Similarly, for tags:
CREATE TABLE tags (
tag_id SERIAL PRIMARY KEY,
name VARCHAR(255) UNIQUE NOT NULL -- "#Python", "#Tutorial", etc.
);
CREATE TABLE video_tags (
video_id INT REFERENCES videos(video_id),
tag_id INT REFERENCES tags(tag_id),
PRIMARY KEY (video_id, tag_id)
);💡 Engagement Tracking
5. Interactions: The Pulse of YouTube
CREATE TABLE interactions (
interaction_id SERIAL PRIMARY KEY,
user_id INT REFERENCES users(user_id),
video_id INT REFERENCES videos(video_id),
interaction_type VARCHAR(20) CHECK (
interaction_type IN ('view', 'like', 'comment')
),
comment_text TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);This schema captures:
Views: Tracked with minimal storage (no additional data needed)
Likes: Simple boolean-like records
Comments: Stores both the action metadata and text content
The CHECK constraint ensures data quality by restricting interaction types.
⚡ Performance Optimizations
Strategic Indexing
CREATE INDEX idx_video_title ON videos(title); -- Search optimization
CREATE INDEX idx_channel_name ON channels(name); -- Channel discovery
CREATE INDEX idx_interaction_video_id ON interactions(video_id); -- Analytics
CREATE INDEX idx_interaction_user_video ON interactions(user_id, video_id); -- PersonalizationView Count Strategies
Option 1: Batch updates (cost-efficient)
UPDATE videos
SET view_count = sub.count
FROM (
SELECT video_id, COUNT(*) as count
FROM interactions
WHERE interaction_type = 'view'
GROUP BY video_id
) sub WHERE videos.video_id = sub.video_id;Option 2: Real-time increment (user experience)
# Application logic example
def record_view(video_id):
execute_sql("UPDATE videos SET view_count = view_count + 1 WHERE video_id = %s", [video_id])🔮 Scaling Considerations
Sharding: Partition videos by upload date or channel ID
Caching: Redis for trending videos and leaderboards
Text Search: PostgreSQL's full-text search or Elasticsearch integration
Analytics: Time-series databases for watch-time metrics
This model provides the foundation that YouTube used in its early days. Modern implementations likely use distributed systems like Spanner, but the relational concepts remain remarkably consistent.
🚀 Handling Viral Video Traffic (Bonus)
When a video hits 10M+ views/hour, YouTube’s infrastructure has to scale reads/writes across thousands of nodes. Common techniques include:
Edge caching with CDNs for fast delivery
Event streaming (Kafka/PubSub) to handle high-volume view events asynchronously
Increment buffers to batch view count updates and avoid write contention
Redis or in-memory counters before syncing to SQL
Horizontal sharding by video ID or creator channel
These optimizations let YouTube absorb massive spikes without locking rows or crashing the backend.
What would you add to this model? Share your thoughts in the comments!